Débuter avec la carte d'évaluation Infineon CY8CKIT-062S2-AI, un kit taillé pour l'Intelligence Artificielle
Je viens de me procurer la carte avec le processeur PSoC 6 du kit d’évaluation Infineon CY8CKIT-062S2-AI, un kit spécialisé dans l’apprentissage automatique (ou ML pour Machine Learning) :

À cet effet, la carte intègre de nombreux capteurs dont les données peuvent être collectées en temps réel pour entraîner les modèles ML :
- radar (détection de présence, tracking) ;
- microphone à technologie MEMS (Micro-Electro-Mechanical Systems);
- pression atmosphérique barométrique (300-1200 hPa) ;
- centrale inertielle de mesure IMU 6 axes (accéléromètre et gyroscope).
La plateforme complète comprend la suite DEEPCRAFT™ Studio pour le développement complet d’une solution ML en partant de la collecte et l’étiquetage des données, la création et l’entraînement de modèles optimisés, jusqu’à leur déploiement sur la carte cible du kit Infineon.
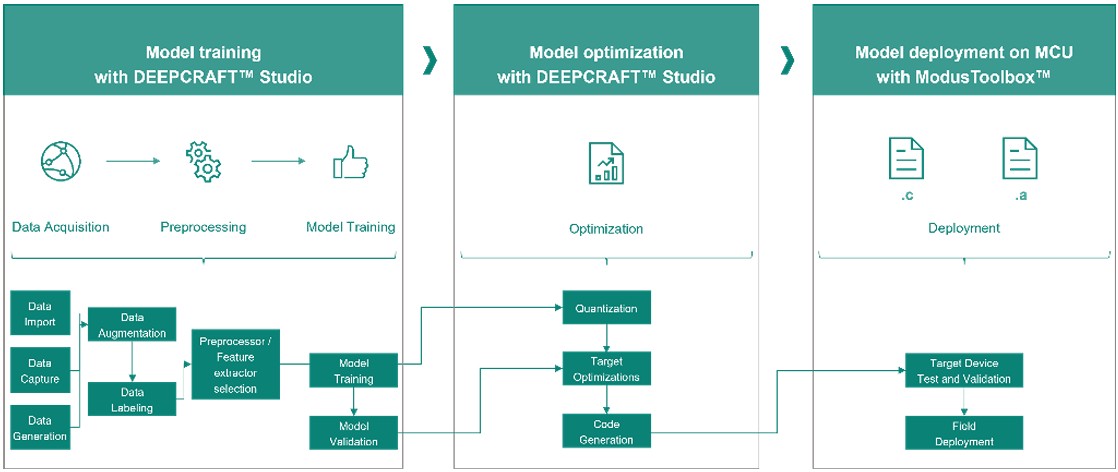 Flux de travail DEEPCRAFT™ Studio, d’après le document CY8CKIT-062S2-AI Product Brief
Flux de travail DEEPCRAFT™ Studio, d’après le document CY8CKIT-062S2-AI Product Brief
Voyons un exemple d’apprentissage automatique (un projet par classification) grâce à un modèle Starter fourni par DEEPCRAFT™ Studio :
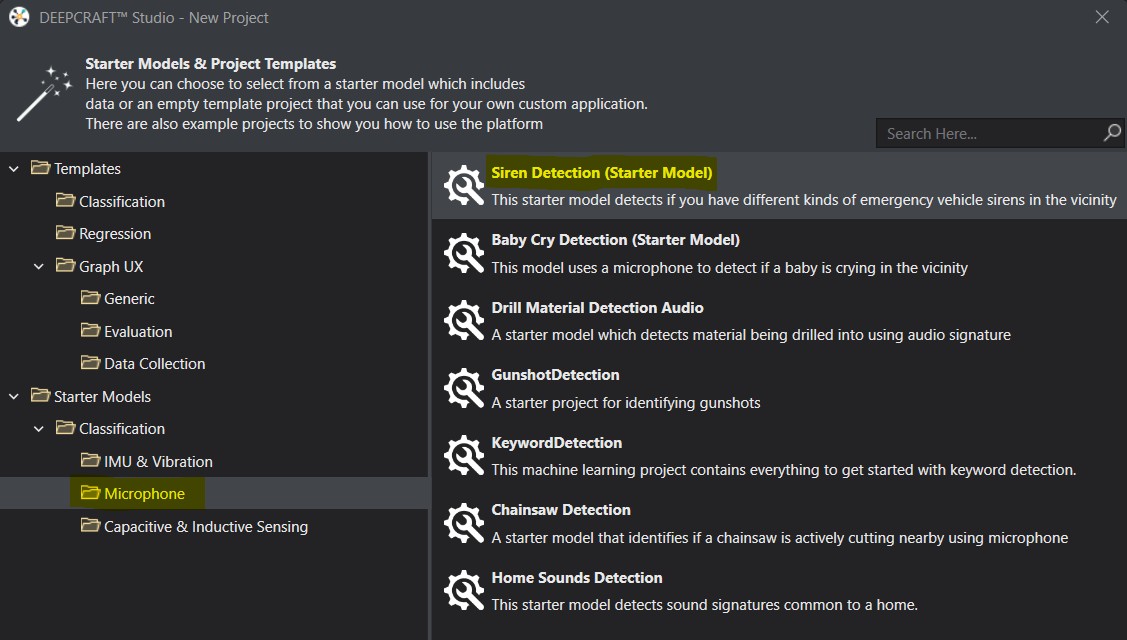 Starter Model - détection de bruit de sirènes de véhicules d’urgence
Starter Model - détection de bruit de sirènes de véhicules d’urgence
Collecte des données en temps réel, étiquetage et préparation des données
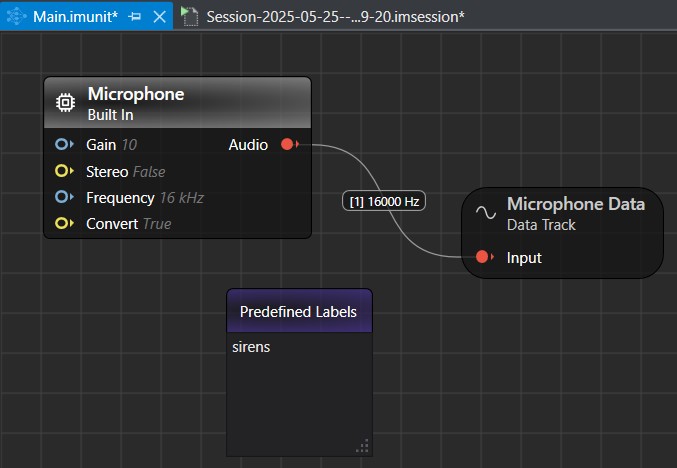
Un firmware flashé par défaut dans la carte fait des acquisitions en continu des données de chaque capteur et transmet les données par le port USB grâce à un protocole de streaming. Dans DEEPCRAFT™ Studio, vous pouvez créer un flux de travail à la souris dans l’outil Graph UX pour, dans un premier temps, faire l’acquisition et le traitement des données, ici avec le microphone intégré à la carte qui est reconnu immédiatement :
Vous pouvez alors enregistrer des sessions de vos bruits de sirène, et étiqueter les données (ici, avec le label sirens) pendant le Live ou en repassant l’enregistrement après coup :
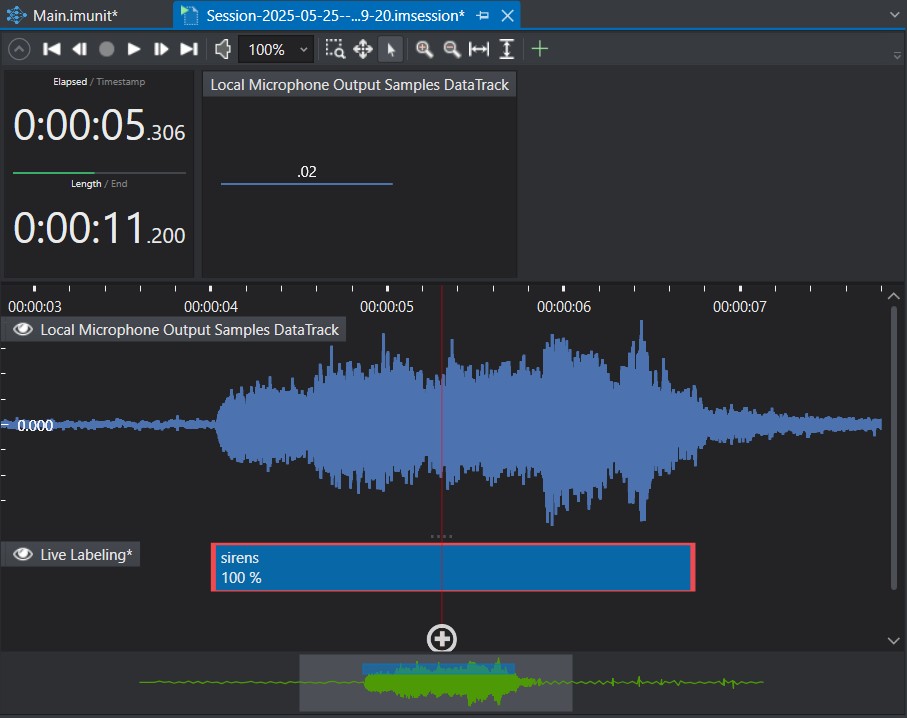
Ce projet Starter comprend déjà de nombreux enregistrements de sirènes diverses avec suffisamment d’ambiances en fond sonore pour un apprentissage de qualité (des bruits d’ambiance peuvent être ajoutés à part et servir à « augmenter » les bruits de sirène).
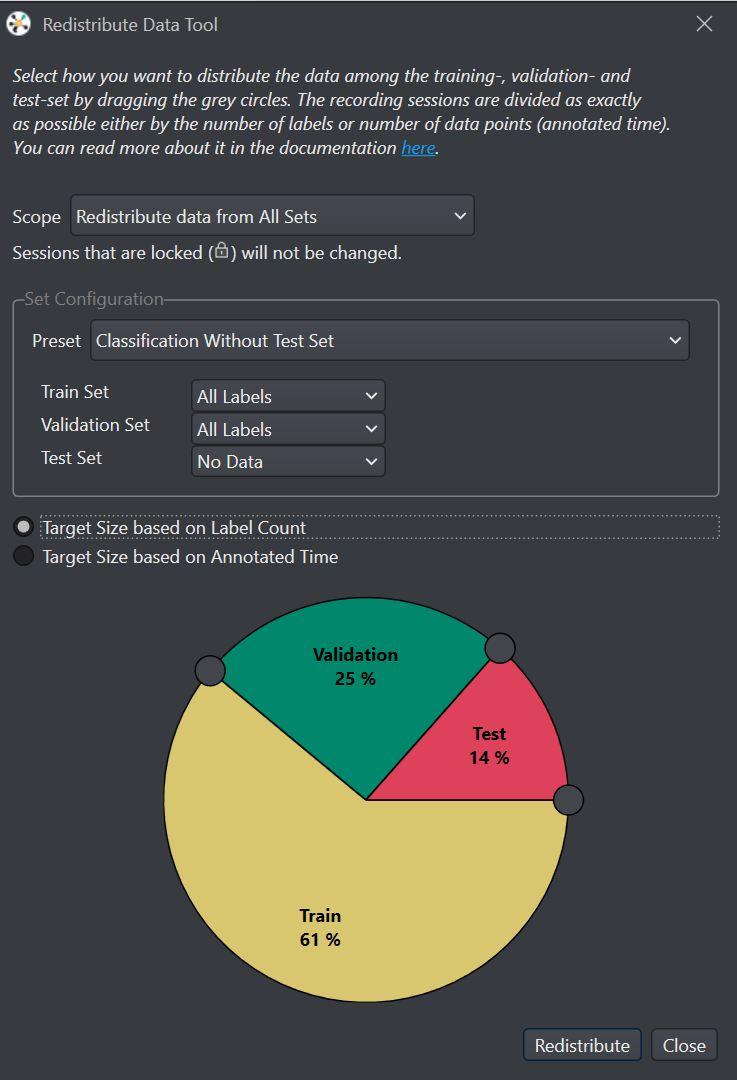
Les données doivent être réparties en trois jeux :
- jeu de données pour l’entraînement des modèles (training set) ;
- jeu de données pour la validation des modèles pour tester et évaluer les performances du modèle pendant l’entraînement (validation set) ;
- jeu de données de test à la fin de l’entraînement pour évaluer les performances d’un modèle sur un jeu de données qui lui est inconnu (test set).
Un outil permet d’automatiser cette redistribution des données :
Le préprocesseur
C’est une étape nécessaire, mais délicate. Avant d’entraîner le modèle, les données doivent être nettoyées et transformées. On définit séquentiellement des couches (layers) de prétraitement, chaque couche traitant ou transformant les données avant de les transmettre à la couche suivante :
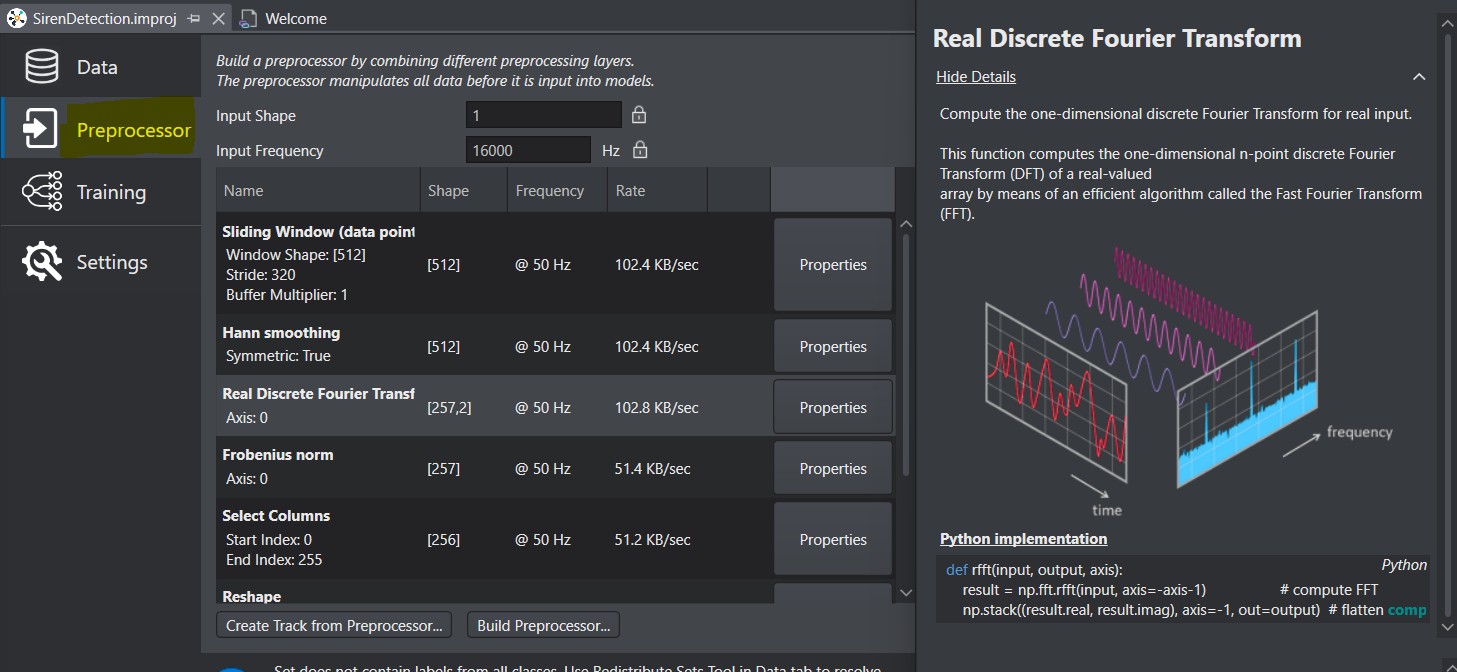
Sur la copie d’écran ci-dessus, on commence par définir une fenêtre glissante (Sliding Windows).
Le fichier audio est une suite de valeurs numériques échantillonnées à 16kHz. La fenêtre glissante prend un bloc de données (ici, shape=512 échantillons) et le traite comme une unité. Ensuite, la fenêtre se décale légèrement (ici, stride=320 échantillons plus loin) et un nouveau bloc est analysé. La fréquence des données en sortie de cette couche est bien de 16000/320=50Hz. Les données sont aussi transformées (shape=[512]), car chaque fenêtre glissante produit un vecteur de 512 valeurs. Il faudra tenir compte de cette transformation en entrée de la couche suivante.
Le prétraitement suivant est un filtre (Hann smoothing) pour réduire les variations brusques, suivi d’une couche d’analyse fréquentielle avec une transformée de Fourier discrète (Real Discrete Fourier Transform : ne conserve que la composante réelle du signal). Les données en sortie de la couche sont encore transformées [257, 2] (257 échantillons, amplitude et phase ?).
Et ce n’est pas fini, je passe sur les étapes de normalisation et de transformation à suivre. Il n’y a rien d’évident dans cette phase du préprocesseur, car il faut un minimum de notions sur le traitement du signal et sur comment sont transformées les données. Mais on peut reprendre les layers des modèles Starter et essayer de comprendre les étapes en visualisant les effets grâce à l’interface Graph UX vue plus haut :
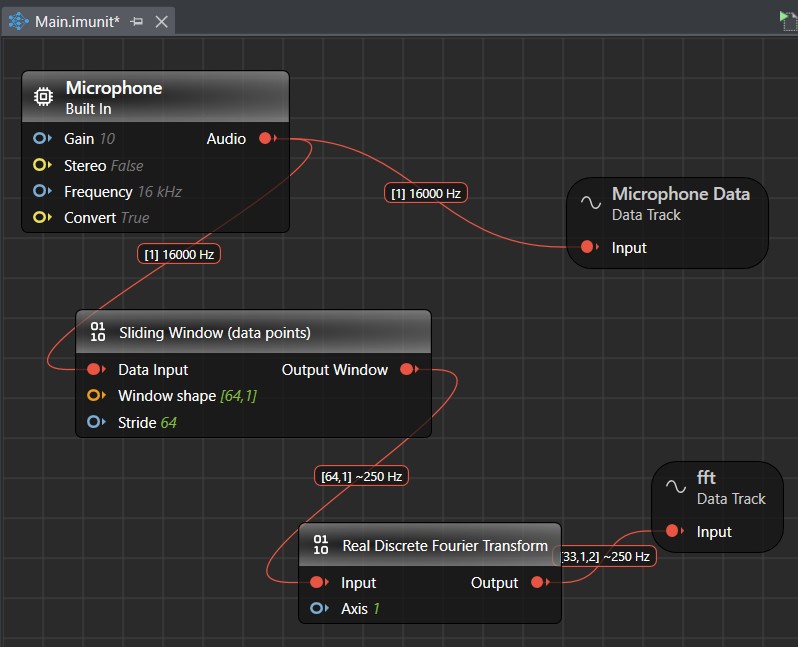 Création de visualisation de différentes transformations
Création de visualisation de différentes transformations
Une fois les couches de prétraitements définies, on peut générer une piste de prétraitement pour évaluer ces transformations avant l’entraînement du modèle (Create Track from Preprocessor…). Finalement, on génère ce prétraitement (Build Preprocessor…), ce qui va compiler les traitements et créer un fichier Python regroupant toutes les transformations définies dans le préprocesseur.
Formation, entraînement et évaluation du modèle
Le « modèle » est essentiellement l’algorithme d’Intelligence Artificielle, par exemple un réseau de neurones entraîné, qui va ici essayer de reconnaître un motif dans les données sonores prétraitées afin de faire des prédictions (est-ce un bruit de sirène ? ou non ?). Avant d’entraîner le modèle, il faut encore le définir, et cela reste une affaire de spécialistes en Intelligence Artificielle (spécialiste que je ne suis pas :-( ).
Mais avant d’entraîner des modèles (Start New Training Job…), on génère une liste de modèles (Generate Model List…) en passant par un assistant ML :
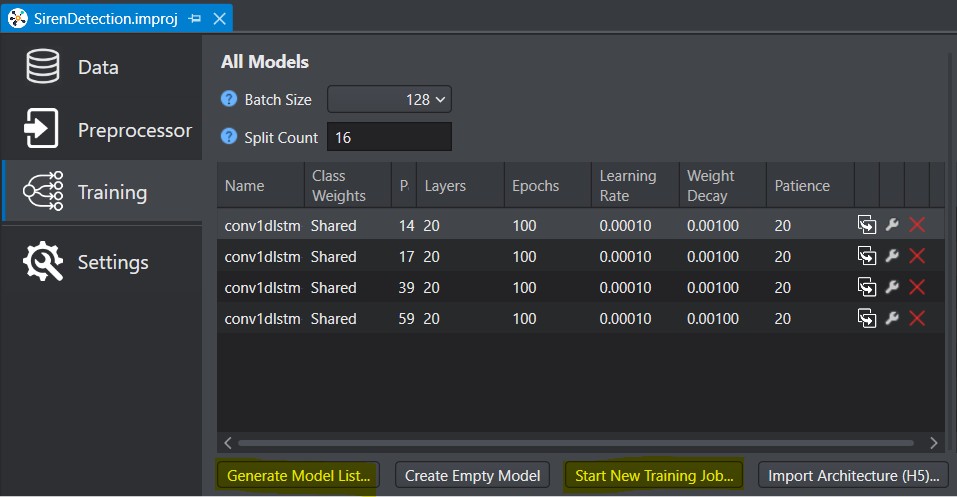
Quatre modèles ont été générés ici, prêts à être envoyés sur le Cloud d’Imagimob pour entraînement. Que le meilleur gagne..
Voici le résultat renvoyé à la fin de l’entraînement :
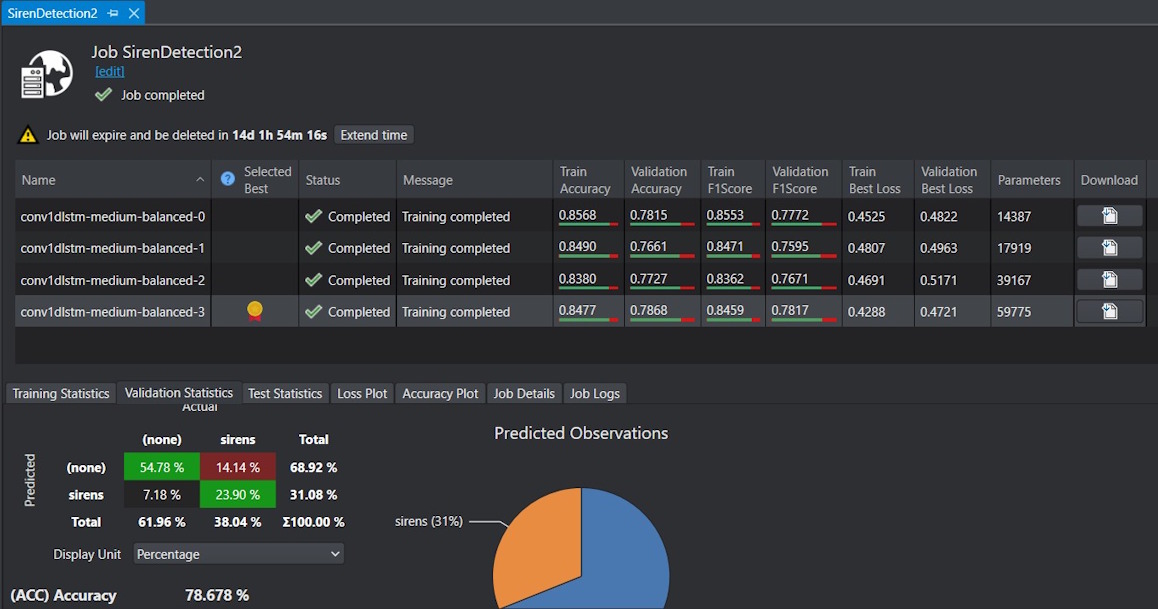
Et les résultats ne sont pas terribles, même pour le best model. Avec environ 24% de vrais positifs (TP) et 14% de faux positifs (FP) sur le jeu de validation (Validation Set), il semble que le modèle ait des difficultés à détecter correctement les sirènes tout en générant trop de fausses alertes. Ce modèle Starter doit être optimisé, où j’ai manqué une étape… Je retiens quand même ce modèle et le télécharge (bouton download).
Génération du code et déploiement
Après l’entraînement et l’évaluation du modèle retenu, l’étape suivante est la génération de code optimisé pour la cible :
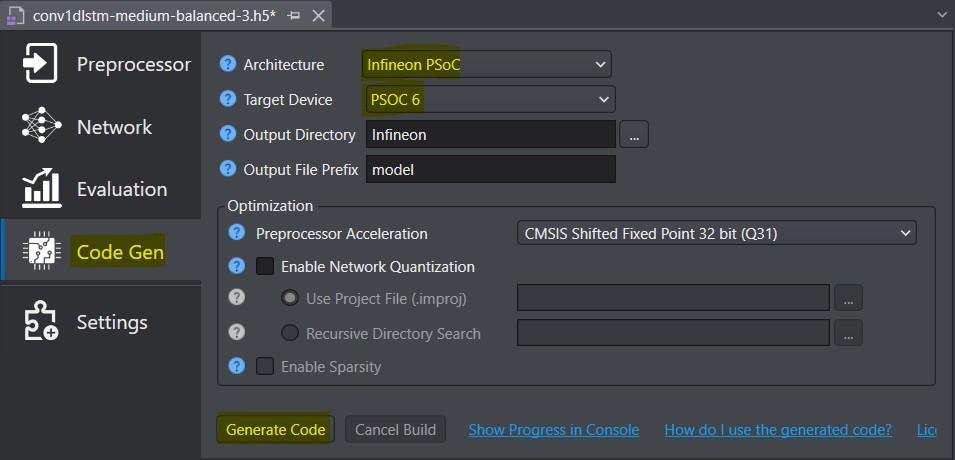
La génération va créer des fichiers model.c et model.h.
Il reste à déployer le code sur la carte CY8CKIT-062S2-AI à l’aide de ModusToolbox, l’environnement de développement d’Infineon pour les microcontrôleurs PSoC 6. Dans ModusToolbox, on crée une nouvelle application, et après avoir sélectionné la cible CY8CKIT-062S2-AI, on choisit le template : DEEPCRAFT deploy Model Audio. Une fenêtre prévient que les fichiers model.c et model.h devront être remplacés par ceux que vous avez fini par générer dans DEEPCRAFT™ Studio :
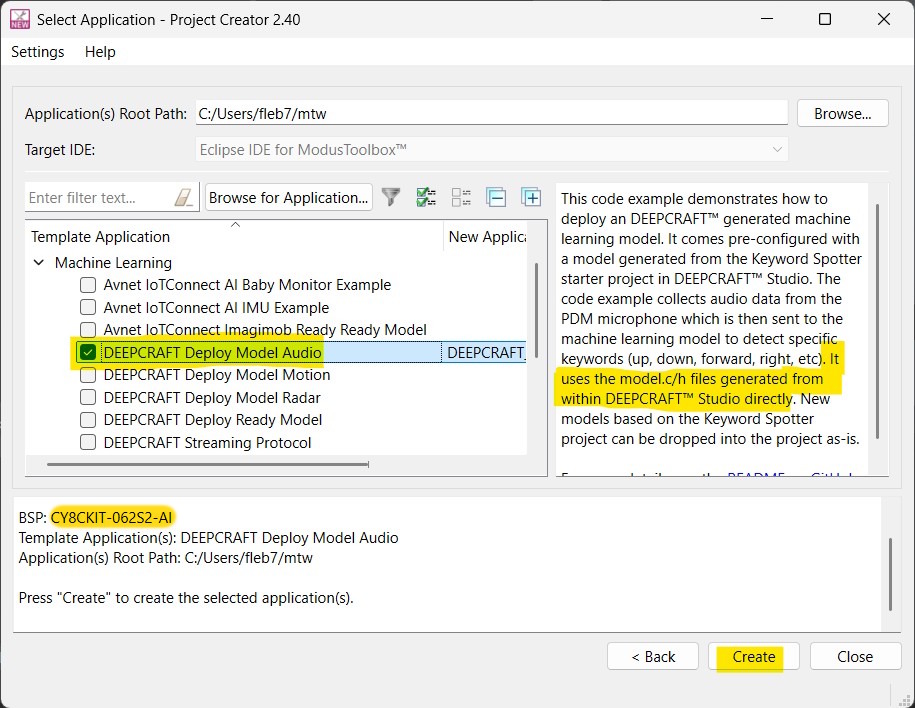
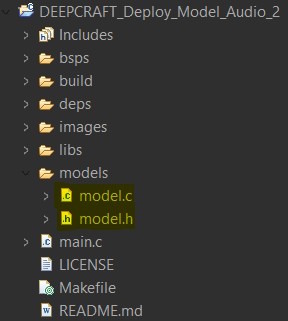 Fichiers model.c et model.h à remplacer dans le code généré
Fichiers model.c et model.h à remplacer dans le code généré
Il reste à compiler le projet (make build) et à le flasher dans la carte (make program) :
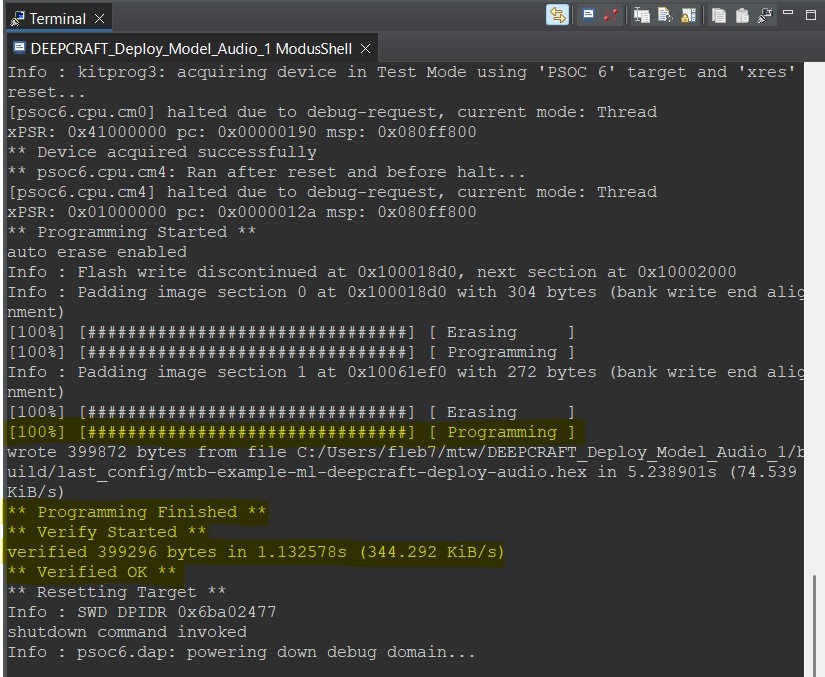
Conclusion
Voici une vidéo où je teste la détection de bruit de sirènes. Le microphone de la carte capte les sons générés depuis un site spécialisé sur Internet, et l’application renvoie les résultats par le port USB dans un terminal série (COM) :
La détection ne fonctionne pas si mal…
En conclusion, je dirais que le développeur a à sa disposition une suite d’outils très puissants pour rapidement déployer des applications de Machine Learning. Il reste que l’Intelligence Artificielle reste une affaire de spécialistes, et que vous risquez de rencontrer pas mal d’obstacles si vous ne maîtrisez pas cette science. Il me faut donc espérer que les nombreux assistants feront des propositions suffisamment correctes par défaut.
J’ai survolé les étapes de création d’une application Starter, mais vous trouverez plus de détails depuis la documentation de DEEPCRAFT™ Studio et celle d’Infineon.
J’ai d’autres Starter Models à découvrir avec les autres capteurs…